
Alex Ratner
Snorkel / UW / Stanford
Github |
Google |
Twitter
Email: ajratner at gmail.com
Latest News
- [5/31/2020] Upcoming talk at the MSR Frontiers in Machine Learning event (7/23).
- [5/27/2020] Our work using Snorkel to extract chemical reactions from biomedical literature is in press!
- [5/1/20] Our work on applying Snorkel to medical imaging and monitoring in the cross-modal is in press!
- [9/4/19] New paper accepted to NeurIPS on slicing functions for monitoring and modeling subsets or slices of datasets; see tutorial in Snorkel.
- [8/15/19] Very excited to release Snorkel v0.9! Release notes here.
One of the key bottlenecks in building machine learning systems today is creating and managing training datasets. Instead of labeling data by hand, I work on enabling users to interact with the modern ML stack by programmatically building and managing training datasets. These weak supervision approaches can lead to applications built in days or weeks, rather than months or years. I’m very fortunate to work with the Snorkel team and members of the Hazy, Info, StatsML, DAWN, and QIAI labs.
Research Projects
Data Programming + Snorkel

|
Snorkel enables users to quickly and easily label, augment, and structure training datasets by writing programmatic operators rather than labeling and managing data by hand. For more on Snorkel, check out snorkel.org, and our release notes on the new version! |
Publications
Research Highlights | All Publications
Programmatic Labeling as Weak Supervision

Labeling training data is one of the biggest bottlenecks in machine learning today. My work investigates whether users can train models without any hand-labeled training data, instead writing labeling functions, which programmatically label data using weak supervision strategies like heuristics, knowledge bases, or other models. These labeling functions can have arbitrary accuracies and correlations, leading to new systems, algorithmic, and theoretical challenges. For more here, check out Snorkel.
-
Extracting Chemical Reactions from Text using Snorkel. Emily Mallory, Matthieu de Rochemonteix, Alexander Ratner, Ambika Acharya, Christopher Ré, Roselie Bright, Russ Altman. BMC Bioinformatics 2020.
-
Cross-Modal Data Programming Enables Rapid Medical Machine Learning. Jared Dunnmon*, Alexander Ratner*, Nishith Khandwala, Khaled Saab, Matthew Markert, Hersh Sagreiya, Roger Goldman, Christopher Lee-Messer, Matthew P. Lungren, Daniel L. Rubin, Christopher Ré. Patterns 2020.
-
Slice-based Learning: A Programming Model for Residual Learning in Critical Data Slices. Vincent Chen, Sen Wu, Alex Ratner, Jen Weng, Christopher Ré. NeurIPS 2019. [Project]
-
Snorkel: Rapid Training Data Creation with Weak Supervision (Extended Best Of Version). Alex Ratner, Stephen Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Christopher Ré. VLDBJ 2019. [Project]
-
Interactive Programmatic Labeling for Weak Supervision. Benjamin Cohen-Wang, Steve Mussmann, Alexander Ratner, Christopher Ré. KDD Data Collection, Curation, and Labeling for Mining and Learning Workshop 2019.
-
Doubly Weak Supervision of Deep Learning Models for Head CT. Khaled Saab, Roger Goldman, Jared Dunnmon, Alexander Ratner, Hersh Sagreiya, Christopher Ré, Daniel L. Rubin. MICCAI 2019.
-
A Machine-Compiled Database of Genome-Wide Association Studies. Volodymyr Kuleshov, Jialin Ding, Christopher Vo, Braden Hancock, Alexander Ratner, Yang Li, Christopher Ré, Serafim Batzoglou, Michael Snyder. Nature Communications 2019.
-
Osprey: Weak Supervision of Imbalanced Extraction Problems without Code. Eran Bringer, Abraham Israeli, Alexander Ratner, Christopher Ré. SIGMOD DEEM Workshop 2019.
-
Learning Dependency Structures for Weak Supervision Models. Paroma Varma, Frederic Sala, Ann He, Alexander Ratner, Christopher Ré. ICML 2019.
-
Improving Sample Complexity with Observational Supervision. Khaled Saab, Jared Dunnmon, Alexander Ratner, Daniel L. Rubin, Christopher Ré. ICLR Learning with Limited Labeled Data (LLD) Workshop 2019.
-
Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale. Stephen H. Bach, Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, Souvik Sen, Alexander Ratner, Braden Hancock, Houman Alborzi, Rahul Kuchhal, Christopher Ré, Rob Malkin. SIGMOD (Industrial) 2019.
-
Snorkel: Rapid Training Data Creation with Weak Supervision. Alex Ratner, Stephen Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Christopher Ré. VLDB 2018. [Blog] [Project] [Poster] [Slides] [Coverage: O'Reilly, EETimes, InfoWorld] ["Best Of" VLDB 2018]
-
Cross-Modal Data Programming for Medical Images. Nishith Khandwala, Alex Ratner, Jared Dunnmon, Roger Goldman, Matt Lungren, Daniel Rubin, Christopher Ré. NeurIPS ML4H Workshop 2017.
-
Learning the Structure of Generative Models without Labeled Data. Stephen Bach, Bryan He, Alex Ratner, Christopher Ré. ICML 2017. [Blog] [Tutorial]
-
A Machine-Compiled Database of Genome-Wide Association Studies. Volodymyr Kuleshov, Braden Hancock, Alex Ratner, Christopher Ré, Serafim Batzaglou, Michael Snyder. NeurIPS ML4H Workshop 2016. [Poster]
-
Data Programming: Creating Large Training Sets, Quickly. Alex Ratner, Christopher De Sa, Sen Wu, Daniel Selsam, Christopher Ré. NeurIPS 2016. [Blog] [Video] [Poster]
- See more papers
Multi-Task Weak Supervision

Multi-task learning is an increasingly popular approach for jointly modeling several related tasks. However, multi-task learning models require multiple large, hand-labeled training sets. My work here focuses on using weak supervision instead. We see this enabling a new paradigm where users rapidly label tens to hundreds of tasks in dynamic, noisy ways, and are investigating systems and approaches for supporting this massively multi-task regime. For initial steps, check out Snorkel MeTaL.
-
Training Complex Models with Multi-Task Weak Supervision. Alex Ratner, Braden Hancock, Jared Dunnmon, Frederic Sala, Shreyash Pandey, Christopher Ré. AAAI 2019. [Project] [Poster] [Oral]
-
The Role of Massively Multi-Task and Weak Supervision in Software 2.0. Alex Ratner, Braden Hancock, Christopher Ré. CIDR 2019.
-
Snorkel MeTaL: Weak Supervision for Multi-Task Learning. Alex Ratner, Braden Hancock, Jared Dunnmon, Roger Goldman, Christopher Ré. SIGMOD DEEM Workshop 2018. [Project]
Data Augmentation as Weak Supervision
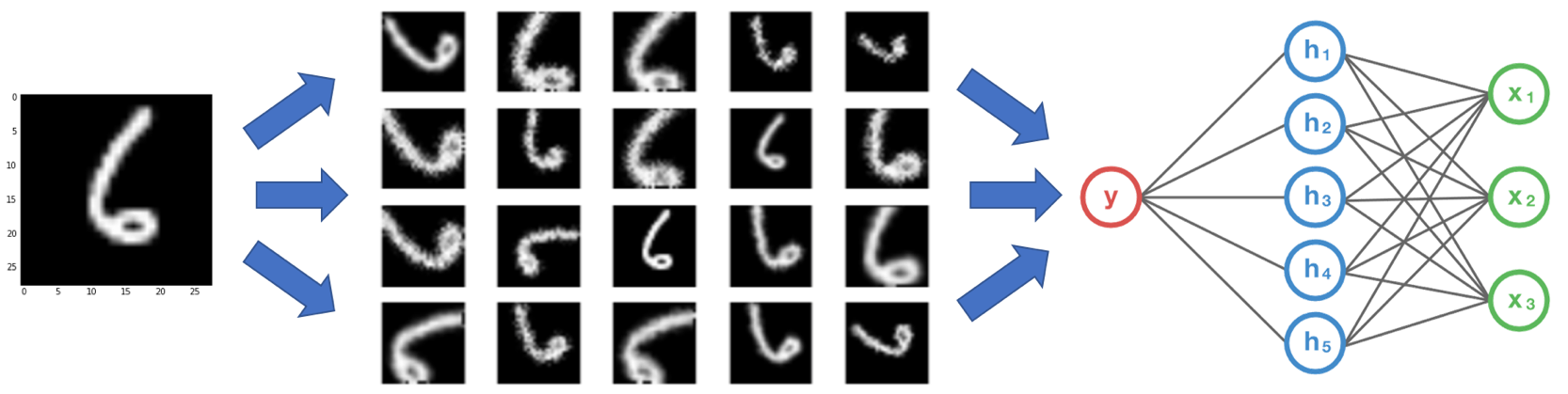
Data augmentation is the increasingly critical practice of expanding small labeled training sets by creating transformed copies of data points in ways that preserve their class labels. Effectively, this is a simple, model-agnostic way for users to inject their knowledge of domain- and task-specific invariances, and my work here investigates how we can support and accelerate this powerful form of weak supervision.
-
A Kernel Theory of Modern Data Augmentation. Tri Dao, Albert Gu, Alex Ratner, Virginia Smith, Christopher De Sa, Christopher Ré. ICML 2019.
-
Learning to Compose Domain-Specific Transformations for Data Augmentation. Alex Ratner*, Henry Ehrenberg*, Zeshan Hussain, Jared Dunnmon, Christopher Ré. NeurIPS 2017. [Blog] [Project] [Video] [Poster]
Other
-
Accelerating Machine Learning with Training Data Management. Alex Ratner. Stanford PhD Thesis 2019.
-
MLSys: The New Frontier of Machine Learning Systems. Alexander Ratner, Dan Alistarh, Gustavo Alonso, David G. Andersen, Peter Bailis, Sarah Bird, Nicholas Carlini, Bryan Catanzaro, Jennifer Chayes, Eric Chung, Bill Dally, Jeff Dean, Inderjit S. Dhillon, Alexandros Dimakis, Pradeep Dubey, Charles Elkan, Grigori Fursin, Gregory R. Ganger, Lise Getoor, Phillip B. Gibbons, Garth A. Gibson, Joseph E. Gonzalez, Justin Gottschlich, Song Han, Kim Hazelwood, Furong Huang, Martin Jaggi, Kevin Jamieson, Michael I. Jordan, Gauri Joshi, Rania Khalaf, Jason Knight, Jakub Konečný, Tim Kraska, Arun Kumar, Anastasios Kyrillidis, Aparna Lakshmiratan, Jing Li , Samuel Madden, H. Brendan McMahan, Erik Meijer, Ioannis Mitliagkas, Rajat Monga, Derek Murray, Kunle Olukotun, Dimitris Papailiopoulos, Gennady Pekhimenko, Christopher Ré, Theodoros Rekatsinas, Afshin Rostamizadeh, Christopher De Sa, Hanie Sedghi, Siddhartha Sen, Virginia Smith, Alex Smola, Dawn Song, Evan Sparks, Ion Stoica, Vivienne Sze, Madeleine Udell, Joaquin Vanschoren, Shivaram Venkataraman, Rashmi Vinayak, Markus Weimer, Andrew Gordon Wilson, Eric Xing, Matei Zaharia, Ce Zhang, Ameet Talwalkar. 2019.
- See more papers
-
Extracting Chemical Reactions from Text using Snorkel. Emily Mallory, Matthieu de Rochemonteix, Alexander Ratner, Ambika Acharya, Christopher Ré, Roselie Bright, Russ Altman. BMC Bioinformatics 2020.
-
Cross-Modal Data Programming Enables Rapid Medical Machine Learning. Jared Dunnmon*, Alexander Ratner*, Nishith Khandwala, Khaled Saab, Matthew Markert, Hersh Sagreiya, Roger Goldman, Christopher Lee-Messer, Matthew P. Lungren, Daniel L. Rubin, Christopher Ré. Patterns 2020.
-
Slice-based Learning: A Programming Model for Residual Learning in Critical Data Slices. Vincent Chen, Sen Wu, Alex Ratner, Jen Weng, Christopher Ré. NeurIPS 2019. [Project]
-
Accelerating Machine Learning with Training Data Management. Alex Ratner. Stanford PhD Thesis 2019.
-
Interactive Programmatic Labeling for Weak Supervision. Benjamin Cohen-Wang, Steve Mussmann, Alexander Ratner, Christopher Ré. KDD Data Collection, Curation, and Labeling for Mining and Learning Workshop 2019.
-
A Machine-Compiled Database of Genome-Wide Association Studies. Volodymyr Kuleshov, Jialin Ding, Christopher Vo, Braden Hancock, Alexander Ratner, Yang Li, Christopher Ré, Serafim Batzoglou, Michael Snyder. Nature Communications 2019.
-
Doubly Weak Supervision of Deep Learning Models for Head CT. Khaled Saab, Roger Goldman, Jared Dunnmon, Alexander Ratner, Hersh Sagreiya, Christopher Ré, Daniel L. Rubin. MICCAI 2019.
-
A Kernel Theory of Modern Data Augmentation. Tri Dao, Albert Gu, Alex Ratner, Virginia Smith, Christopher De Sa, Christopher Ré. ICML 2019.
-
Learning Dependency Structures for Weak Supervision Models. Paroma Varma, Frederic Sala, Ann He, Alexander Ratner, Christopher Ré. ICML 2019.
-
Osprey: Weak Supervision of Imbalanced Extraction Problems without Code. Eran Bringer, Abraham Israeli, Alexander Ratner, Christopher Ré. SIGMOD DEEM Workshop 2019.
-
Snorkel: Rapid Training Data Creation with Weak Supervision (Extended Best Of Version). Alex Ratner, Stephen Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Christopher Ré. VLDBJ 2019. [Project]
-
Improving Sample Complexity with Observational Supervision. Khaled Saab, Jared Dunnmon, Alexander Ratner, Daniel L. Rubin, Christopher Ré. ICLR Learning with Limited Labeled Data (LLD) Workshop 2019.
-
MLSys: The New Frontier of Machine Learning Systems. Alexander Ratner, Dan Alistarh, Gustavo Alonso, David G. Andersen, Peter Bailis, Sarah Bird, Nicholas Carlini, Bryan Catanzaro, Jennifer Chayes, Eric Chung, Bill Dally, Jeff Dean, Inderjit S. Dhillon, Alexandros Dimakis, Pradeep Dubey, Charles Elkan, Grigori Fursin, Gregory R. Ganger, Lise Getoor, Phillip B. Gibbons, Garth A. Gibson, Joseph E. Gonzalez, Justin Gottschlich, Song Han, Kim Hazelwood, Furong Huang, Martin Jaggi, Kevin Jamieson, Michael I. Jordan, Gauri Joshi, Rania Khalaf, Jason Knight, Jakub Konečný, Tim Kraska, Arun Kumar, Anastasios Kyrillidis, Aparna Lakshmiratan, Jing Li , Samuel Madden, H. Brendan McMahan, Erik Meijer, Ioannis Mitliagkas, Rajat Monga, Derek Murray, Kunle Olukotun, Dimitris Papailiopoulos, Gennady Pekhimenko, Christopher Ré, Theodoros Rekatsinas, Afshin Rostamizadeh, Christopher De Sa, Hanie Sedghi, Siddhartha Sen, Virginia Smith, Alex Smola, Dawn Song, Evan Sparks, Ion Stoica, Vivienne Sze, Madeleine Udell, Joaquin Vanschoren, Shivaram Venkataraman, Rashmi Vinayak, Markus Weimer, Andrew Gordon Wilson, Eric Xing, Matei Zaharia, Ce Zhang, Ameet Talwalkar. 2019.
-
Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale. Stephen H. Bach, Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, Souvik Sen, Alexander Ratner, Braden Hancock, Houman Alborzi, Rahul Kuchhal, Christopher Ré, Rob Malkin. SIGMOD (Industrial) 2019.
-
The Role of Massively Multi-Task and Weak Supervision in Software 2.0. Alex Ratner, Braden Hancock, Christopher Ré. CIDR 2019.
-
Training Complex Models with Multi-Task Weak Supervision. Alex Ratner, Braden Hancock, Jared Dunnmon, Frederic Sala, Shreyash Pandey, Christopher Ré. AAAI 2019. [Project] [Poster] [Oral]
-
Snorkel: Rapid Training Data Creation with Weak Supervision. Alex Ratner, Stephen Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Christopher Ré. VLDB 2018. [Blog] [Project] [Poster] [Slides] [Coverage: O'Reilly, EETimes, InfoWorld] ["Best Of" VLDB 2018]
-
Knowledge Base Construction in the Machine Learning Era. Alex Ratner, Christopher Ré. ACM Queue 2018.
-
Snorkel MeTaL: Weak Supervision for Multi-Task Learning. Alex Ratner, Braden Hancock, Jared Dunnmon, Roger Goldman, Christopher Ré. SIGMOD DEEM Workshop 2018. [Project]
-
Cross-Modal Data Programming for Medical Images. Nishith Khandwala, Alex Ratner, Jared Dunnmon, Roger Goldman, Matt Lungren, Daniel Rubin, Christopher Ré. NeurIPS ML4H Workshop 2017.
-
Learning to Compose Domain-Specific Transformations for Data Augmentation. Alex Ratner*, Henry Ehrenberg*, Zeshan Hussain, Jared Dunnmon, Christopher Ré. NeurIPS 2017. [Blog] [Project] [Video] [Poster]
-
AMELIE Accelerates Mendelian Patient Diagnosis Directly from the Primary Literature. Johannes Birgmeier, Maximilian Haeussler, Cole A. Deisseroth, Karthik A. Jagadeesh, Alexander J. Ratner, Harendra Guturu, Aaron M. Wenger, Peter D. Stenson, David N. Cooper, Christopher Ré, Jonathan A. Bernstein, Gill Bejerano. BioRxiv 2017. [Project]
-
Learning the Structure of Generative Models without Labeled Data. Stephen Bach, Bryan He, Alex Ratner, Christopher Ré. ICML 2017. [Blog] [Tutorial]
-
DeepDive: Declarative Knowledge Base Construction. Ce Zhang, Christopher Ré, Michael Cafarella, Christopher De Sa, Alex Ratner, Jaeho Shin, Feiran Wang, Sen Wu. Communications of the ACM 2017.
-
Snorkel: Fast Training Set Generation for Information Extraction. Alex Ratner, Stephen Bach, Henry Ehrenberg, Christopher Ré. SIGMOD Demo 2017. [Project]
-
SwellShark: A Generative Model for Biomedical Named Entity Recognition without Labeled Data. Jason Fries, Sen Wu, Alexander J. Ratner, Christopher Ré. ArXiv 2017.
-
Snorkel: A System for Lightweight Extraction. Alex Ratner, Stephen Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Christopher Ré. CIDR Abstract 2017.
-
Data Programming: Creating Large Training Sets, Quickly. Alex Ratner, Christopher De Sa, Sen Wu, Daniel Selsam, Christopher Ré. NeurIPS 2016. [Blog] [Video] [Poster]
-
A Machine-Compiled Database of Genome-Wide Association Studies. Volodymyr Kuleshov, Braden Hancock, Alex Ratner, Christopher Ré, Serafim Batzaglou, Michael Snyder. NeurIPS ML4H Workshop 2016. [Poster]
-
Data Programming with DDLite: Putting Humans in a Different Part of the Loop. Henry Ehrenberg, Jaeho Shin, Alex Ratner, Jason Fries, Christopher Ré. HILDA @ SIGMOD 2016.
-
Deepdive: Declarative Knowledge Base Construction. Christopher De Sa, Alex Ratner, Christopher Ré, Jaeho Shin, Feiran Wang, Sen Wu, Ce Zhang. ACM SIGMOD Record 2016.
2020
2019
2018
2017
2016
Blog Posts
Some high level thoughts and tutorials; for more blog posts, see paper-specific ones above, and check out https://www.snorkel.org/blog/
[8/15/19] Introducing the New Snorkel
[3/14/19] Harnessing Organizational Knowledge for Machine Learning [Google AI blog]
[12/4/18] Software 2.0 and the Paradigm Shift in Programming ML Systems
[7/12/17] Weak Supervision: The New Programming Paradigm for Machine Learning
[12/15/16] Data Programming in TensorFlow [tutorial]
Older News
[6/4/19] Two new ML + medicine papers using Snorkel: extracting GWAS studies (Nature Communications) and doubly-weak supervision for head CT (MICCAI 2019); see pubs.
[4/21/19] Two papers accepted to ICML, on structure learning for weak supervision and data augmentation.
[4/20/19] New workshop paper on using observational (eye tracker) data to improve image classification.
[3/31/19] SysML whitepaper is posted!
[3/29/19] Manuscript (under review) of our work on applying Snorkel to radiology and neurology applications just posted.
[4/17/19] Upcoming talks: Excited to be talking at Data Council in SF about using Snorkel for data science and data engineering (4/17); CMU Tepper School (4/19); ODSC East in Boston (5/3); RAAIS in London (6/28)
[3/14/19] New post on the Google AI blog about our work deploying Snorkel there; also covered on ZDNet and Towards Data Science.
[3/14/19] Submission deadline for our ICLR 2019 workshop, Learning from Limited Labeled Data (LLD), postponed till 3/24
[2/13/19] Our report with Google on using Snorkel at industrial scale accepted to SIGMOD 2019
[2/1/19] Talking about our work on multi-task supervision @ AAAI- 10am
[1/14/19] Talking about our vision for massively multi-task learning @ CIDR
[11/29/18] Our workshop, Learning from Limited Labeled Data (LLD): Weak Supervision and Beyond, will be hosted at ICLR this year
[11/6/18] Hosting the 2nd Snorkel workshop on biomedical KBC
[10/31/18] Our paper on multi-task weak supervision accepted to AAAI
[10/31/18] Presenting at ODSC West on 11/3 in SF
[10/22/18] Our vision paper on massively multi-task weak supervision accepted to CIDR 2019
[8/28/18] Looking forward to presenting on Snorkel at VLDB in Rio
[7/28/18] Excited to be joining the organizing committee of SysML 2019; submission deadline is 9/28
[7/12/18] Just wrapped up a day on Snorkel at the ACM Data Science Summer School; check out the materials here.
[6/15/18] Giving a talk about our current work on weakly-supervised MTL at DEEM.
[2/3/18] Talking about programming machine learning models via weak supervision at the AAAI DeLBP workshop.
[1/22/18] Talking about Snorkel, weak supervision, and information extraction on the Data Engineering podcast.
[12/15/2017] Papers and talk slides from our NeurIPS LLD 2017 workshop posted here.
[10/15/2017] Our paper on Snorkel accepted to VLDB 2018! New blog post here.
[12/9/2017] Excited to be starting a workshop on weak supervision at NeurIPS 2017: Learning from Limited Labeled Data: Weak Supervision and Beyond.
[9/26/2017] Speaking about Data Programming + Snorkel at Strata Data Conference in NYC.
[9/4/2017] Our work on learning data augmentation models accepted to NeursIPS 2017! Check out the blog post + code
[7/19/2017] Snorkel workshop hosted by the Mobilize Center happening! Materials and videos online soon.
[7/12/2017] New blog post on weak supervision - send us your feedback
[7/10/2017] Version 0.6 of Snorkel has been released
[6/8/2017] Talking about data programming + Snorkel on the O'Reilly Data Show Podcast.